

In this article, we’ll look at how Tellor permissionlessly enables gasless governance, decentralized cross-chain communication, on-chain API calls and more, with Query Types.
Introduction
Tellor is an immutable decentralized oracle protocol that allows users to request specific pieces of data and incentivizes reporters to place those values in an on-chain database. Tellor is compatible with virtually any type of verifiable data through the use of standardized data-type identification that is understood by reporters and users alike. Whether you need Spot Prices, a TWAP, cross-chain calldata or a random number, the Tellor system is equipped with a methodology for anyone to build out these standardized ways of making data requests – we call them Query Types. By offering unparalleled versatility, customization, and scalability, Query Types empower users to create data feeds tailored to their unique needs, in a decentralized and permissionless way.
How does this work? To understand Query Types, we’ll first reacquaint ourselves with some key Tellor terminologies:
- reporters: A permissionless network of staked addresses that compete to fulfill data queries generated by users who receive “tips” as payment.
- tip: a transaction that includes a payment for answering (submitting for) a corresponding query that is submitted to the Tellor oracle contract. A tip txn has 3 inputs: the QueryID, QueryData, and an Amount.
- submitValue: The function a reporter must call to report data on-chain to the oracle. The submitValue function requires these inputs: queryID, queryData, nonce, and value.
Permissionless Coordination
The Tellor protocol is permissionless. It is designed to allow anyone to participate, enabling censorship-resistance and decentralization. Using open-source software, anyone can become a reporter by staking TRB, submit values, read values, make a query (tip), or dispute incorrect values. These functionsare hard-coded in immutable contracts, but what a user inputs into them is open-ended. See the tip function for example:
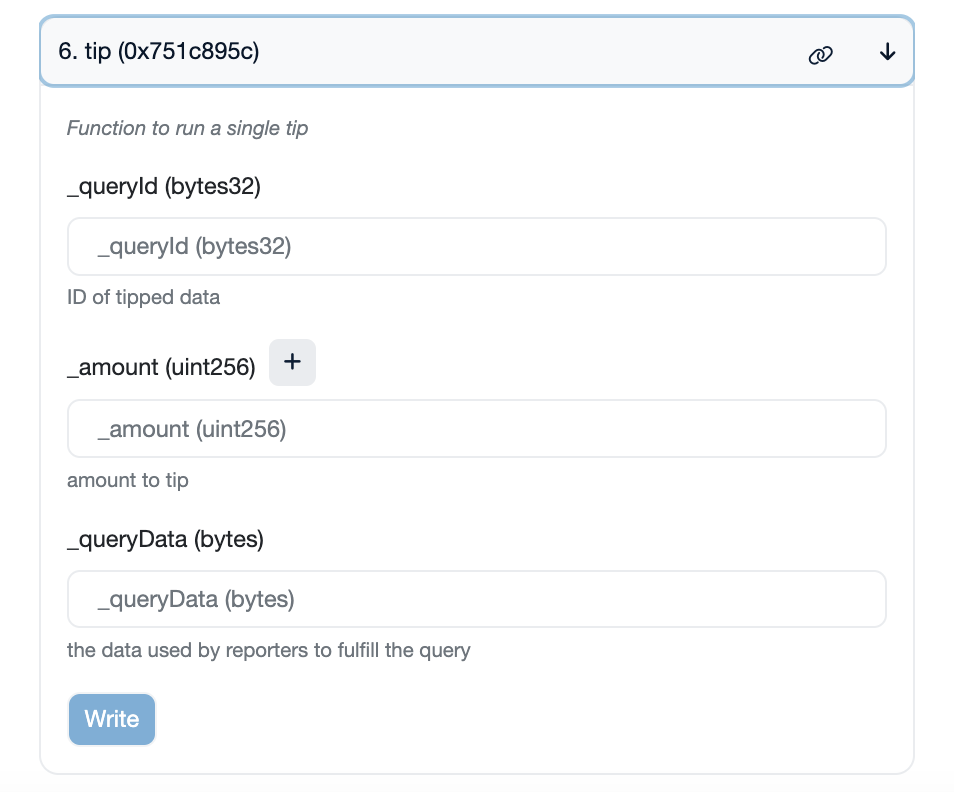
The tip function and its components – queryID, amount, and queryData – are pre-established within an unchangeable smart contract. However, the user’s choices for specific queryIDs and queryData are defined in a guide that’s stored off-chain. This gives the tip function a flexible aspect. In other words, as long as users continue to input fresh information into this function, the function can evolve and expand its functionality. As a final point in this explanation, the amount is a quantity of TRB tokens selected by the user to fund the tip. This is an example of how users have the power to shape the behavior of the protocol.
This dynamic is a crucial aspect of the Tellor oracle protocol. It maintains immutability, while still being adaptable and scalable in capacity and capability. This unique balance allows Tellor to transcend limitations of immutable protocols, enabling continuous evolution and growth.
Let’s delve deeper into what queryIDs and queryData are, and how they tie in with Query Types.
Life Cycle of a Tellor Data Request
In order to fully understand Query Types you need to understand the “life cycle” of a data request or query in the Tellor system.
Every Query has these 4 components – Query Type, Query Descriptor, queryData, and queryId.
- The Query Type is the specification for custom data you want to receive from the Tellor oracle. It defines the parameters of a query that users can input for their specific requests. The Query Type name is also used as an input to generate your queryData.
- The Query Descriptor is a unique string representation of the query, including all parameter values. Example: { type: “SpotPrice”, asset: “eth”, currency: “usd” }
- The Query Data is a bytes encoding of the descriptor, and all its parameters. The Query Data provides the instructions, in a sense, on how reporters need to interpret the request and format a response. It also informs voters on how to verify the data in case of a dispute.
- The Query ID is a keccak256 hash of the Query Data field. In order to query the Tellor oracle, you’ll need to have a Query Type so that you can then generate Query Data and its hash, the Query ID which are required as inputs to make your Query, which is a data request.
To request data, users call the tip function as we illustrated earlier, inputting the queryID and queryData for the data they want placed on-chain, along with some amount of payment (the tip). Tellor’s network of staked data reporters is listening for these tips using open-source client sofware that can (in most cases) automatically fulfill the data request accurately according to the given inputs.
Projects building on Tellor have already defined many useful query types like spotPrice, TWAP, NFTmarketIndex, and ChatGPTResponse. A full list can be found on our Github.
Now let’s talk about how you can create your own!
Creating a Query Type
To create a new Query Type, make an issue in the tellor dataSpecs repo following this example template:
- Type Name: Choose a unique name for your new Query Type (e.g., SpotPrice, Snapshot).
- Description: Provide a general description of the Query Type, including its purpose and suggested use cases.
- Query Parameters: Define the parameters of your new Query Type (See an example here), including:
- Parameter name
- Description and value specification
- Valid ABI type
- The parameter order required for the Query Data bytes
- Response Type: Specify the ABI type and a boolean signifying whether the response will be packed or not when encoded to bytes.
- Query Data: Generate the Query Data for an instance of your new Query Type by encoding the parameter values in the specified order.
- Query ID: Generate a unique Query ID by getting the bytes32 value of the keccak hash of the Query Data.
- JSON Representation: Create a JSON representation of your new Query Type, including the type name, parameters, and their corresponding value types, as well as the expected response type for the query.
- Example: Provide a working example mapping of all the inputs and parameters to a valid Query ID.
- Dispute Considerations: Keep in mind that following this guide does not prevent you from being disputed or guarantee reporters will properly put a value on-chain. Focus on communication and working with reporters to prevent unnecessary disputes and encourage monitoring and punishment of bad data.
- Suggested Data Sources: List possible data sources where reporters can retrieve the query’s response. Mention APIs available for reporters to programmatically retrieve the data for your query’s expected response and multiple possible sources for the expected response.
Examples
Here are some in-production examples of QueryTypes showing the versatility and customization potential of the Tellor oracle system.
- TWAP:
The TWAP (Time-Weighted Average Price) query type returns the average price of an asset in a specified currency over a given timespan. Its parameters include asset, currency, and timespan.
The EVMCall query type allows users to request that data be read from one EVM chain and written to another. Information like token balances, NFT ownership, and other public data can be moved between EVM blockchains without requiring a bridge. Parameters for the EVMCall query type include chainId, contractAddress, and calldata.
The Snapshot query type returns the proposal result for a given proposal ID (an IPFS hash for a specific proposal) from Snapshot. It has one parameter, proposalId, which must be a valid proposal on Snapshot.
The TellorRNG query type has one parameter, timestamp, which specifies the timestamp after which to find the next Bitcoin blockhash. The query response consists of a bytes32 value.
The ComboQuery returns an array of other queries. It has one parameter, queryData, which is an array of valid queryData values that hash to the desired query IDs.
The SpotPrice query type returns the spot price of an asset in a specified currency. Its parameters include asset and currency. The query response consists of a single 256-bit value with 18 decimals of precision.
These QueryTypes showcase the ability to retrieve a wide range of data from pricing information to on-chain data and beyond. we’re envisioning an exciting shift towards further decentralization.
Decentralizing The Data Specs
At the time of this writing, the specifications for these Query Types live in a public repository maintained by the Tellor core team. Anyone can submit a pull request to add a new Query Type or submit an issue requesting our help. This works great, but doesn’t align with our ultimate goal of protocol autonomy. We want to make sure that Tellor can thrive without input from the Tellor core team. Right now that is possible, but we want to make it practical. That means no entity should be relied on to host and maintain a repo for these data specs, instead this should be offloaded to a decentralized network like filecoin and IPFS. It’s a fun challenge to make this a reality, and we have already begun taking steps in building this out. In the near future all specifications for Query Types will live on-chain, and owned by the community.
Conclusion
As we conclude, it becomes clear that understanding QueryTypes is not only crucial but also empowering for anyone aiming to interact with the Tellor system. By following this guide, you’ll be able to craft your own custom QueryTypes, enabling you to request specific data from the Tellor oracle that aligns with your unique needs. However, don’t overlook the importance of active communication and collaborative interactions with reporters, as these are key elements in achieving accurate and reliable data reporting within the Tellor ecosystem.
Query Types are more than just a feature; they represent the foundation of Tellor’s decentralized and permissionless data reporting and validation network. With the power of Query Types, users have the potential to unlock unprecedented capabilities of blockchain technology, steering the course towards a more liberated, censorship-resistant, and decentralized digital world. The future of data is here, and it’s permissionlessly customizable.


