
Background
Usage of the current Tellor protocol is expanding, with the system having demonstrated its security across various EVM networks. However, the constant-change of crypto has led the Tellor team to recognize trends that signal potential challenges for the existing structure of the Tellor protocol in the upcoming years, specifically:
1. Emergence of Application-Specific Chains:
- Thousands of chains, each tailored for specific applications, are expected to emerge.
2. No Dominant Native System:
- No single native system will prevail. Many projects will operate as individual L1s, while others may utilize DA layers like Ethereum, Celestia, or use shared security zones as hubs.
- Hubs will be characterized by high costs and slow transactions. Utilizing these central points will become highly inefficient, with the possibility of token transfer costs on mainnet Ethereum exceeding $1,000 in the next decade.
3. Advancements in Trustless Bridging:
- With the emergence of light client bridges (zk or not), the traditional hub-and-spoke model (that many monolithic chains are aiming for) will likely be disrupted.
- The distinction between a sovereign L2 and an L1 with a trustless bridge will be minimal.
4. Increased Speed, Finality, and Security Needs:
- As crypto use cases begin to rival web2 alternatives, there will be a continuous demand for improved speed, finality, and security in transactions.
Preparing Tellor for the Future
So, how should we shape Tellor both as a protocol and as a company for the future? How can we create the best possible oracle? How do we make the Tellor protocol the oracle of choice for projects that want to integrate fast and secure data on any chain without compromising core principles?
Non-Negotiables:
- Decentralization: The Tellor protocol must remain decentralized with minimal DAO or governance risk.
- Interoperability: The Tellor protocol must work on any chain without needing to bridge the token there.
- Handling Non-Deterministic Queries: Just relying on APIs isn’t sufficient. The focus should be on managed sets and high data quality. Tellor should function as a data creator, not merely a data provider, and focus on soft/social consensus.
Additional Goals:
- Capability to Manage Large Data Volumes: For example, handling survey data, or large input sets both quickly and affordably for on and off-chain use.
- Enhanced Security: The system should be infinitely secure, with individual protocols able to add security on their end.
- Framework for Non-EVM Chains: The system should be designed to accommodate both EVM and non-EVM chains.
- Additive Expansion: The addition of new chains or protocols should be complementary rather than competitive.
- Limiting MEV: The current widespread practice of MEV and front-running of reports by Tellor protocol reporters should be addressed, as it would benefit the system to reduce this practice.
By addressing these concerns and embracing these goals, Tellor can be strategically positioned to thrive in the rapidly evolving crypto landscape. This direction will ensure that the Tellor protocol continues to function as a leading oracle while adapting to the ever-changing needs and demands of the crypto ecosystem.
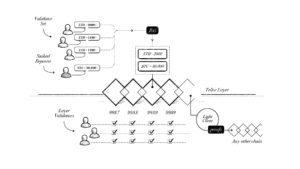
Tellor Layer
Tellor Layer is the next evolution for the Tellor protocol. It is a system for coming to consensus on any data and will be created as a stand alone chain built with the Cosmos SDK and CometBFT consensus mechanism.
Overview
Tellor Layer works by validators submitting an answer to a query. Once one validator submits an answer, all validators need to either submit their own answer to the query or simply validate that someone submitted the value.
Consensus
Validators are not forced to use a standard client and may choose to support any or all oracle queries depending on their individual goals. This flexibility allows for different levels of security for different types of data.
For queries with broad consensus level support, almost all validators of the chain will directly sign off on the information. Examples of this would be API calls, a median of multiple API calls, or some other form of information that is readily available with standardized definitions. Validators will get the information from off-chain (e.g. make an api call), sign the value and then aggregate the information with other validators before putting it on-chain. The median can be accepted as the official value and used right away.
Validators may choose to support more obscure data types as their risk tolerance allows. Users can see what percentage of the validators signed off/ reported on each value. If a minimum of ⅔ of validators report a piece of data, it can be considered finalized. If consensus does not reach a ⅔ threshold, the value can still be read, but it should be considered “optimistic” and taken cautiously. Riskier data should utilize best practices such as implementing a delay.
Tellor Layer will provide major advantages:
- More validators can choose to sign off on each piece of data
- Custom governance contracts by query type or modular governance
These differences lead to several slashing scenarios when a bad value is submitted:
- Reporters and validators can be slashed by consensus of other validators
- Slashing for double signs (Tellor Layer validators cannot sign data, push it to another chain for consumption, and not submit it to Tellor Layer(this would be a double-sign) )1
- Custom slashing via modular governance (dispute resolution associated with the queryID).
Modular Governance
In the old Tellor protocol, all queries used the same governance procedure. With Tellor Layer however, users can select a governance framework that best fits their query specifications. This flexibility is necessary since the verification of some queries can be handled more quickly than others. Whereas whether an API call was valid might be able to be decided and voted on in a matter of hours, a piece of non-deterministic query or subjective data with specific technical knowledge…(e.g. using the Tellor protocol for insurance as in “was this protocol hacked”) might take longer. In this way the Tellor protocol can work as a fast verification mechanism for certain ID’s, and also a decentralized court with delegated jurors and technical experts providing evidence and judgment.
Supported Data
Besides a commitment to decentralization, the Tellor protocol differentiates from other oracles by using non-deterministic data values and by creating, reporting, and maintaining robust data series. The non-deterministic nature of the Tellor protocol architecture allows us to expand support to broader subjective data reports such as survey data, loosely defined, or even evolving query specifications.
non-deterministic queries
The Tellor protocol is not just middleware reading API’s. There are several reasons we’ve shied away from just providing access to API’s, the main one being that it’s not decentralized or robust for applications. When a user wants a price feed for example (say ETH/USD), you could require them to maintain a list of API’s that correspond to what values they want (e.g. coinbase, binance, coingecko api’s). The problem is that these endpoints can be a) censored by the hosting party and b) changed (either maliciously or just a routine version update). We’ve found many protocols wanting full decentralization would much rather have the oracle (Tellor protocol) handle the governance process. They’re much more open to accepting oracle ownership of the definition of a “valid price of ETH” where the reporter/oracle consensus can choose which endpoints to hit.
Similar to the current Tellor protocol structure, users can own data specifications for a given queryId or rely on the Tellor protocol network to manage robust sets for specific use cases (fair market prices, eod settlement prices, or other manipulation resistant feeds). Combining best practices from traditional financial settlement or liquidation price behaviors, as well as user-defined slashing guidelines, Tellor continues to set standards in the defi space, pushing users to reject the basic oracle approach of just reading an api.
subjective data reports
The Tellor protocol will continue to be able to be used for broad subjective reports including private endpoints, subjective legal interpretations, and decentralized survey data. For projects like household surveys (e.g. CPI, unemployment, etc.), the staking requirement can be very low (many of these things are very difficult to verify) and the outliers can be handled at an aggregate level (similar to current survey practices). The Tellor protocol will handle this data (on-chain or via IPFS for larger sets) and reporting methodology to enable a trustless (and likely incentivized) decentralized survey apparatus.
The Tellor protocol doesn’t force reporters to support all data. For an ideal generic oracle, the system should support data that not everyone knows or needs to sign off on (e.g. weather in a specific location, paid API’s, had-to-be-there events, etc.). Of course the data becomes more robust when more parties can sign off on it, but given regulatory restrictions and various global locations of a reporter network, flexibility is the key to creating the most decentralized oracle possible that is capable of handling any data request.
MEV Limitations
In Tellor Layer any staked party can sign off on a piece of given data and MEV is no longer an issue. Any validator that wishes to submit a value for a given query can do so. Payment differences between validators will only exist due to which data is supported by each validator.
Using Tellor Layer Data On Other Chains
Tellor Layer data is used on other chains in two ways: a state proof retrieval method and a pull oracle. Both are similar in many ways, namely that values will be passed trustlessly to other chains for usage.
State Proof Retrieval
Values on Tellor Layer are collated into a state proof (merkle tree root) created by chain validators. Chains wishing to consume Tellor Layer data run a light client of the Tellor Layer consensus mechanism, validating the state proof by observing the signatures of validators for updating the proof. Parties wishing to consume oracle data use inclusion proofs2 to reference information in the state proof.
Pull Oracle
Data generated by Tellor Layer can be consumed near instantaneously once on-chain consensus is reached. This works by users grabbing consensus proof and a value from Tellor Layer using either batched signatures or a zk-proof. This proof is then passed with the value to the user’s chain and can be consumed as soon as enough signers have validated the data. Since double signing is prohibited, the user can be assured that their data is secure. For slower, or less supported data (e.g. micro cap coins, decentralized courts, survey data), state proofs are the more cost efficient method.
These are just two ways to read data from Tellor Layer (a standard light client supported by us), however other approaches will likely takehold and make our approach unnecessary (e.g. broader support of IBC3/ XCM, or any trustless, or trusted, data bridge protocols4).
Custom Security
Users will be able to add additional security by adding staking requirements to queryID’s. In the current Tellor protocol, each data submission is only assigned one stake. However, Tellor Layer will allow users to read data more quickly if more validators sign a given query ID. For ETH/USD for instance, a relatively easy to verify and widely supported price, users can require that 2/3rds of the validators sign off the data for each submission. If consensus is not reached, a 5 minute delay can be added to wait for disputes, a sign that the market may be in turmoil and a fair price for the asset is not readily available.
Note that protocols using the Tellor Protocol should still use all best practices including robust data standards and even fallbacks/ governance where social consensus or DAO control is wanted over crypto-economic guarantees.
Forking and upgrade handling
Longer form upgrades to bridge contracts can happen via the oracle itself. Assuming you trust the oracle, upgrades that would require a fork in the bridging contract (e.g. a change in the consensus mechanism or similar) can be handled by the oracle reporting a valid bridging contract on each connected chain. When an upgrade is pending, devs can deploy a new bridging validation contract. By separating out the data read contract and the validation contract, it will allow for upgrades to happen without downtime.
A harder problem for bridging data is how bridged systems can handle forks. Although forks are often seen as something to be avoided at all cost (the btc maxi view), ideally we do use forks as a backstop. Tellor recognizes that a final subjective layer is best for securing these protocols (e.g. we all see that something’s wrong, let’s fork). The problem is that you need a way on each chain to decide which fork is the legitimate one. For this, bridged systems can use their own consensus mechanism to solve this problem, specifically via an escalation layer/ schelling game with infinite rounds ending with the subjective layer of the bridged protocol itself 5. As Tellor Layer matures, forks will likely become less of an issue and protocols should harden this security or remove it altogether.
Tokenomics Changes
None, but can mint tokens if a raise is secured or for incentives to switch for partners. The only action necessary is to move current time-based rewards to a new system (brick oracle address on current contract).
A two-way migration contract will exist from the current Tellor token contract to the new Tellor Layer bridge contract, so as to allow infinite time for exchanges, reporters, and users to move over. There will also be an initial mint of tokens (amount tbd) to bootstrap validator set security.
Philosophical Considerations for the Design and the Future
Building a next generation oracle is difficult, but the harder problem is deciding whether or not we want to build it. Namely, we want to ensure that any version of the Tellor protocol fits with our values and is at the same time built to last.
Some of the questions we’ll keep in mind as we build this include, but are not limited to:
- Does this version of the Tellor protocol create a more equitable, decentralized, and/or sustainable future?
- Tellor’s goal is a future where freedom is enhanced by decentralization and cryptography. Does the new Tellor protocol do this?
- Where is the capture? If censorship resistance and/or decentralization should fail, where will it happen in this system? Are social forks an option with the given structure?
- Will there be a capture of nodes by any institution?
- Is there a proper incentive / ability to run validators or nodes on a solo basis?
- Does this system address CEX or institutional control of tokens?
- Is liquid staking enabled/ a problem?
- How does Tellor Layer scale past the limitations of one chain? Will this chain fill up too?
- Can we just launch a new oracle chain/contract and segment by dataType (bridges, etc.)
- Rollups of our chain? More recursive proofs?
- Do we just increase the block size? Use a DA layer to parse history?
Note, this stuff isn’t a deal breaker and is hard for any oracle, but these are issues we should aim to address and lead the space forward on.
Rationale for Design Choices
The biggest reason we’ve picked our given path is that we’re early, and we don’t want to be beta testers for a scaling product. We’re pushing the envelope on the oracle side, and that’s where our expertise lies. We want something that can realistically work in the next year without breakthroughs in computer science or complete sacrifices of decentralization.
Why a cosmos chain?
We need scale. We need flexibility.
The other options we explored were rollup SDK’s, writing our own chain, an EVM fork, or just a smart contract on a faster chain/L2. After comparing the difficulty, longevity (security is only proven by production), and costs, the Cosmos SDK won out. It’s a flexible choice with a robust ecosystem that we’ve been a fan of for years. In addition to the basic chain SDK, we can piggyback on wallets, bridges, zk proofs, and countless other tools that are built and maintained by the other teams. We want our focus to be on creating the best data possible, and this solution enables that.
If the question is more in regards to “why our own chain” vs just building on someone, this is where we need scale and more throughput than current options afford. Bridging is getting better and easier and if you assume you have a world where that gets solved, running a separate chain is no longer the isolated death that it was at the beginning of the last cycle. We envision app chains to become the norm and trustless bridges to move things across. This is the first step in acknowledging that vision.
Why not a rollup?
To be honest, this was/is a tough decision. We looked into a lot of current rollup structures (OP stack, arbitrum, etc.) and the two issues we found were that a) they’re not decentralized at all, and b) it’s just too expensive to checkpoint to ETH. Since we need to be decentralized, these just aren’t viable paths. We’re oracle experts, not rollup architects. There are other options coming down the pipeline (zk rollups, zkEVM, celestia, etc.), but we find these to be way too early to be usable in a decentralized way any time over the next few years. Not to mention, that as an oracle, we need faster finality than most current L2’s in order to be used across any chain. We can achieve this with an L1, but unfortunately there is a tradeoff between rollup speed and cost (due to how often you checkpoint). We still may go the route of shared security in some way, and are also looking into many designs by teams to have a plug and play consensus for becoming a rollup / your own chain dynamically all from the cosmos sdk. If costs come down, decentralized options become available, and the finality gets quicker, we’ll definitely keep this option open.
Conclusion
The next version of the Tellor protocol is still very much in development. This provides an overview of the direction we’re headed, but feedback, discussion, and criticism are appreciated and encouraged! Reach out if you want to get involved, potentially use the Tellor protocol, or just want to chat about oracle designs.
1 https://old.reddit.com/r/ethdev/comments/10c1azd/cant_the_sync_committee_be_cheaply_bribed_and/
3 https://tutorials.cosmos.network/academy/3-ibc/1-what-is-ibc.html
4 e.g. https://www.herodotus.dev/


